Cilium in EKS and VPC peering
I recently need to setup VPC peering across different EKS clusters. We use Cilium with routing-mode: native . When debugging connectivity issue I refreshed my understanding of how Cilium work in EKS and what needs to be configured in our cases.
Context
In my case I have EKS cluster deployed in different regions with non-overlapping VPC CIDR range. For example
- Region A, EKS cluster with VPC CIDR 10.11.0.0/16
- Region B, EKS cluster with VPC CIDR 10.12.0.0/16.
I want to setup VPC peering so that pod to pod can communicate in these two clusters.
Standard VPC peering is straightforward: make region B VPC requests to peer (requester), and region A VPC, accepter to accept the peering request; finally configure routing table on both ends, route traffic matching CIDR range to the peering.
I created two testing pods. Region A: server side httpbin pod; Region B client side sleep pod. Test is to make curl from client to server.
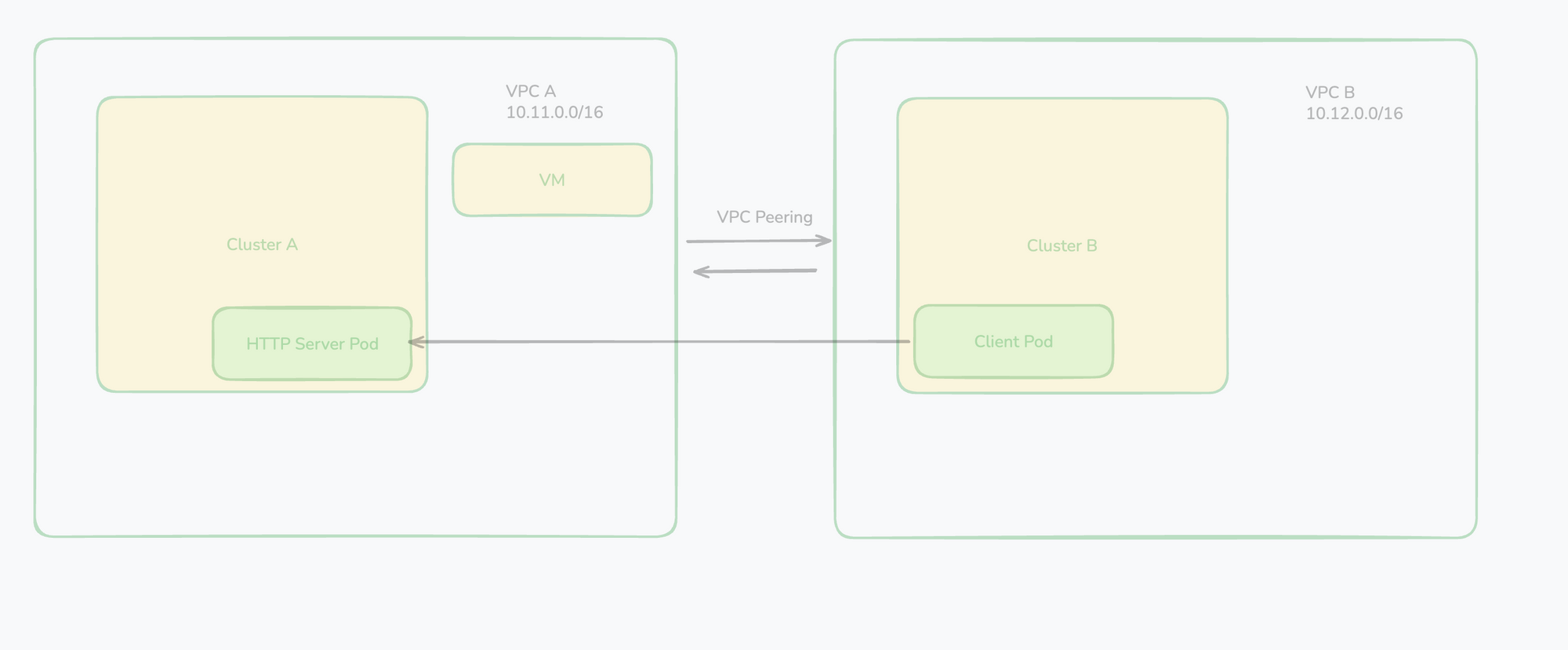
And it does not work, and I checked a few basic things
- Security Group
- Cilium (Kubernetes) network policy.
To ensure everything is configured correctly at infra level, I created a VM in the destination side VPC. Client Pod -> VM ip is successful. So it got to be something on the server side to explain the differences.
Mention sometimes it works, occasionally.
continue debugging story
tcpdump on both client and server side: a) syn sent from client b) syn recieved, but not responded, c) using pwru, seeing the kernel error. set the rp filter would make kernel replies but not useful.
clearly something wrong about eni, ip and routing management.
ENI node and Pod IP
Mental model of their relationship is important.
- One node could have one or multiple ENI cards.
- One ENI cards can have one (primary IP) or mulptile IPs (secondary IP) from AWS associated with it.
- Under our configuration, one ENI ip is used for one pod.
But who manages it? Cilium, yes. As we use ipam: eni mode. https://docs.cilium.io/en/latest/network/concepts/ipam/eni/ documents (CiliumNode CR keep tracks of the mapping of the ENI and pod ip relationship, could be useful in debugging).
Cilium Basics
Cilium components, operator and agent work together. We can expect Cilium operator and agent communicate, agent doing local eBPF, policy management etc. But as the only EKS CNI plugin I expect Cilium also manages ENI attachment to the node and its ENI secondary ip mapping to Pods. In order to do so, Cilium must communicate with AWS api server, but I didn't see any? How come?
Things I verified:
- Cloud Trail tracking the ENI related api calls. They are from individual nodes'
- Cilium operator logs
Attached ENI to instance. Tracking from the code Cilium clearly is
I don't care who assumes the identity whether Cilium agent and operator relay the credential. All I care and confirmed: Cilium does the ENI and ip management. That's it.
Routing
routing-mode: native is configured in my cluster. Under this config, basically Cilium relies on ip rule Linux built-in route table for networking routing. Another config is encapsulation basically UDP packet would be used to encapsulate the internal packet and communicated among Cilium nodes.
- tc ingress only eth0 has the bpf filter program; TODO: relevance? maybe. this is how cilium achieves the routing. check the ip routes.
ip routing table basics
basically ip rule show the high level route decision to look up of another table. ip table <name> contains the specific table rule definition, matching CIDR range, goes to which ethernet device.
$ ip rule
# first column is the priority, smaller the higher priority.
0: from all lookup local
100: from 10.0.1.0/24 lookup isp1
150: from 10.0.2.0/24 lookup isp2
200: from all to 192.168.100.0/24 lookup dmz
300: from 172.16.5.10 lookup isp2
400: from all fwmark 0x1 lookup isp1
500: from all to 8.8.8.8 lookup isp2
32766: from all lookup main
32767: from all lookup default
ip table isp1
default via 203.0.113.1 dev eth1
10.0.0.0/8 dev eth0 scope link
ip table isp2
default via 198.51.100.1 dev eth2
10.0.0.0/8 dev eth0 scope linkComparison and Control
With this background, I feel confident to proceed and asking crucial questions.
This time I also first made an experiment: region a VM client -> region A pod. tcpdump shows the connection goes through eth1 <-> cilium - host veth pair. no eth0 involved, tcpdump details.
region b client -> region A pod: server side tcpdump, traffic coming eth0, returning eth1, details of the tcpdump.
Let's check the IP route on the node as we are using routing native mode.
When VM 10.11.x.x -> 10.11.4.91 / httpbin pod ip / bound to eth1, returning path of the tcp handshake, would be 10.11.4.91 -> 10.11.x.x.. This matches ip rule.
111: from 10.11.4.91 to 10.11.0.0/16 lookup 11
and table 11 means
default via 10.11.0.1 dev eth1 table 11 proto kernel
10.11.0.1 dev eth1 table 11 proto kernel scope linkAnd traffic would flow through eth1 device. and succeeds.
When pod 10.12.x.x. sends the request, by default it would matches the 32766: from all lookup main. This makes it use default via 10.11.0.1 dev eth0 default route. (main is a special key word in the routing table?, not sure) this makes it goes through eth0.
I added another rule ip rule add from 10.11.4.91 to 10.12.0.0/16 lookup 11 priority 111 and then curl from the eu-west-1 pod works! and removes it, fails again.
Solution
Configure ipv4-native-routing-cidr and need to wait for new node. This make sense as changing the ip route dynamically could be dangerous.
Trivia
When the kernel ip_handle_martian_source handles the mistmatched ethernet device, pwru can detect that. But how to detect the routing layer issue? who rejects my packet? maybe pwru is not a good tool for this. as it could be dropped by aws layer.
Conclusion
I used lots of AI's help. but it's important to
- Stop and asked when it's the time to refresh the foundational understanding instead of ad-hoc trying to guess work. When you don't undestand Cilium, my brain is very fuzzy about is it eBPF issue or something else? Who manages that route? etc. But once unerstand the
ip routeand Cilium manages it, and ENI / EC2 model, it's clear what is missing and what needs to be configured. - Use separate chat for individual clear focused sub question as quality degrades with longer chat.
- Make lots of experiments, comparison and control. Not only sending request from cluster B to A but also A -> A when the client is VM.