eBPF LRU map cache trashing
A interesting exploration of eBPF LRU map
Recently working on a networking project using eBPF traffic control ingress, I encountered a counterintuitive behavior with eBPF LRU maps that's worth sharing.
Context
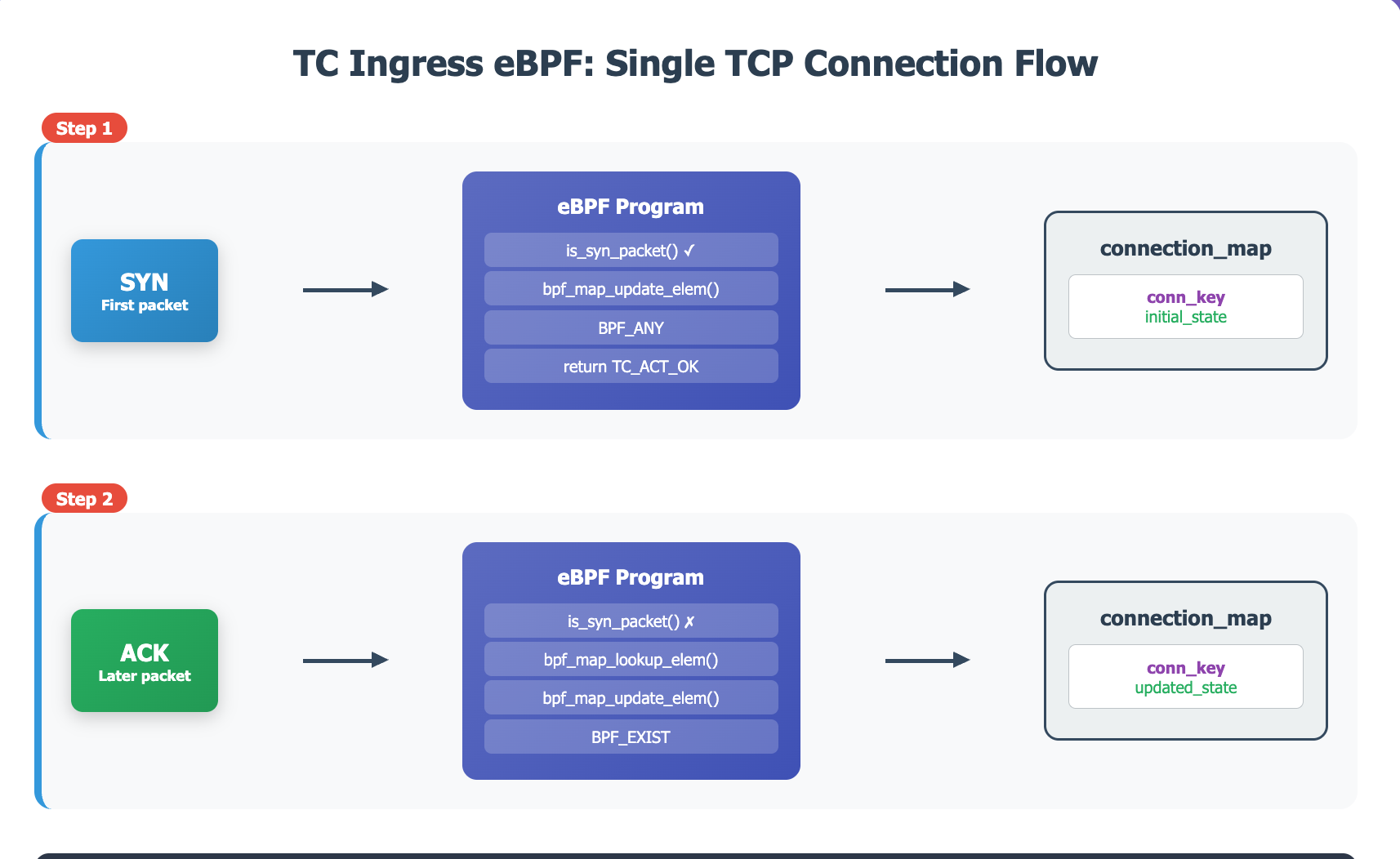
My eBPF program inspect every incoming packet, and update a hash map called connection_map.
struct {
__uint(type, BPF_MAP_TYPE_LRU_HASH);
__uint(max_entries, 200);
__type(key, struct connection_key);
__type(value, struct connection_value);
} connection_map SEC(".maps");
void my_ebpf_program(struct __sk_buff *skb) {
if (is_syn_packet(skb)) {
bpf_update_map_element(&connection_map, &conn_key, initial_state{}, BPF_ANY);
bpf_printk("handle syn packe");
return TC_ACT_OK;
}
// Later on when ACK packet is sent to the server to complete TCP handshake.
connection_value *conn = bpf_map_lookup_elem(&connection_map, &conn_key);
if (!conn) {
bpf_printk("lookup fail");
}
if (bpf_update_elem(&connection_map, &conn_key, &new_conn_val, BPF_EXISS) != 0) {
bpf_printk("update fail!");
}
}This eBPF program is attached to TC ingress filters, for all traffic on lo network interface.
- eBPF map is
BPF_MAP_TYPE_LRU_HASH. Basically this means Kernel is responsible for managing map element eviction based on the access pattern (lookup & update call). Size is 200. - A test client sends 20 TCP connections sequentially to
localhost. - For every connection: SYN packet from the client insert an entry into LRU map. The second packet from the client, ACK packet, would successfully find previous inserted element and update the value.
Problem
I expect that all connections and their packets are processed sequentially as above. bpf_printk for update fail will never get triggered. Instead I observed:
- For the first connection everything is expected.
- For the second connection and the ones afterwards, SYN packet inserting map succeeds; look up succeeds, but
bpf_update_elemfails, and printed outupdate fail.
I further checked return value bpf_update_elem, it's NOEXIST . This means that the map element is evicted.
But how come!? LRU map size is 200. We only creates 20 connections sequentially I don't expect any eviction.
Investigation
Step 1, Confirming it's related to LRU map eviction
To confirm indeed related to LRU map eviction, I did two more experiments:
- Non-LRU map, this behavior is gone.
- Size of LRU map matters: I changed size from 200 to 600, then I see the the updates start to fail from 3rd or 4th connection, instead of 2nd. And when changing to a large size like 65536, the issue never happen!
It has to be related to LRU cache eviction, except that I don't fully understand it.
Step 2, Rule out race condition of the packets processing
Could this be related to data race: multi-core CPUs processes packets, even for the same connection, concurrently and cause something weird? I found out that modern network interface driver / kernel is smart enough to use some hash of packet addresses/ports to try route packets of the same connection to the same CPU core. But concurrent packet processing is still possible. Let's rule out.
I instrumented the eBPF program with bpf_get_smp_processor_idbpf_ktime_get_ns and printed out values for every packet in eBPF programs. With this I see indeed the same connections are, mostly, indeed processed within one CPU cores and everything is sequential.
Accurately speaking, I did see one connection's handshake packets can happen in CPU 1 and then switched to CPU 2 occasionally, but that does not explain our issue.
With such a simple sequential processing model, I am asking myself: could elements with different keys using the same bucket in the hash map? After some research, the answer is no. This left me almost hopeless confused and I almost want to just set a larger size of map and forget about this issue...
Step 3, Unexpected findings of LRU map
Before I really gave up, I decided to read the kernel documentation again. Documentation provides a flow chart for map lookup logic, and one interesting word make me intrigued: LOCAL_FREE_TARGET . The linked commit for LRU cache mentioned:
Since we have acquired the global LRU list lock, it will try to get at most LOCAL_FREE_TARGET elements to the local free list.
The commit description essentially covers a few thing.
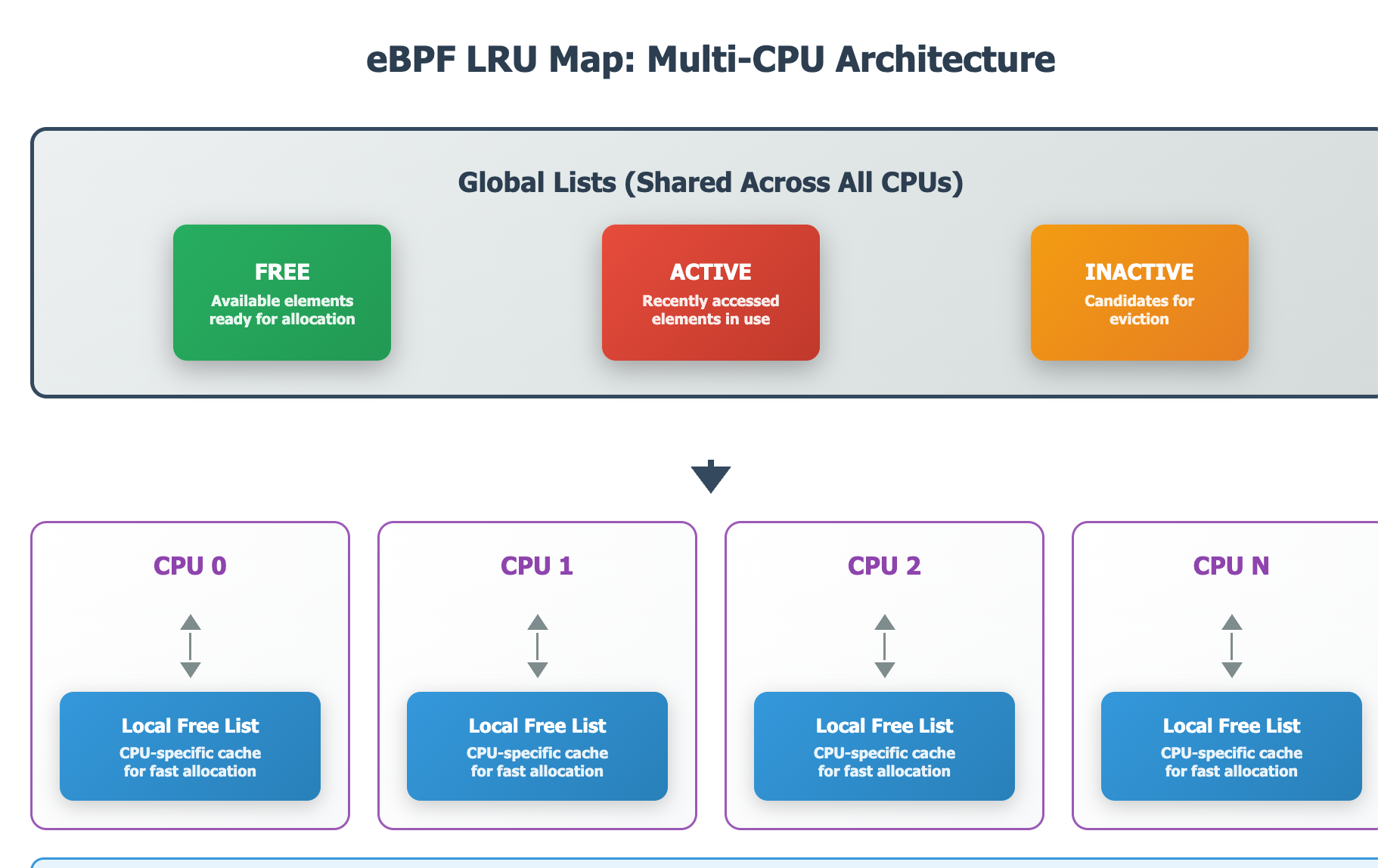
- LRU map contains a few global lists (free, active, inactive elements);
- Per CPU would try to grab elements from the global lists and maintain its own free-list. Every time it would try to grab at least
LOCAL_FREE_TARGET - Active/inactive/free lists are rotated and managed along LRU map access.
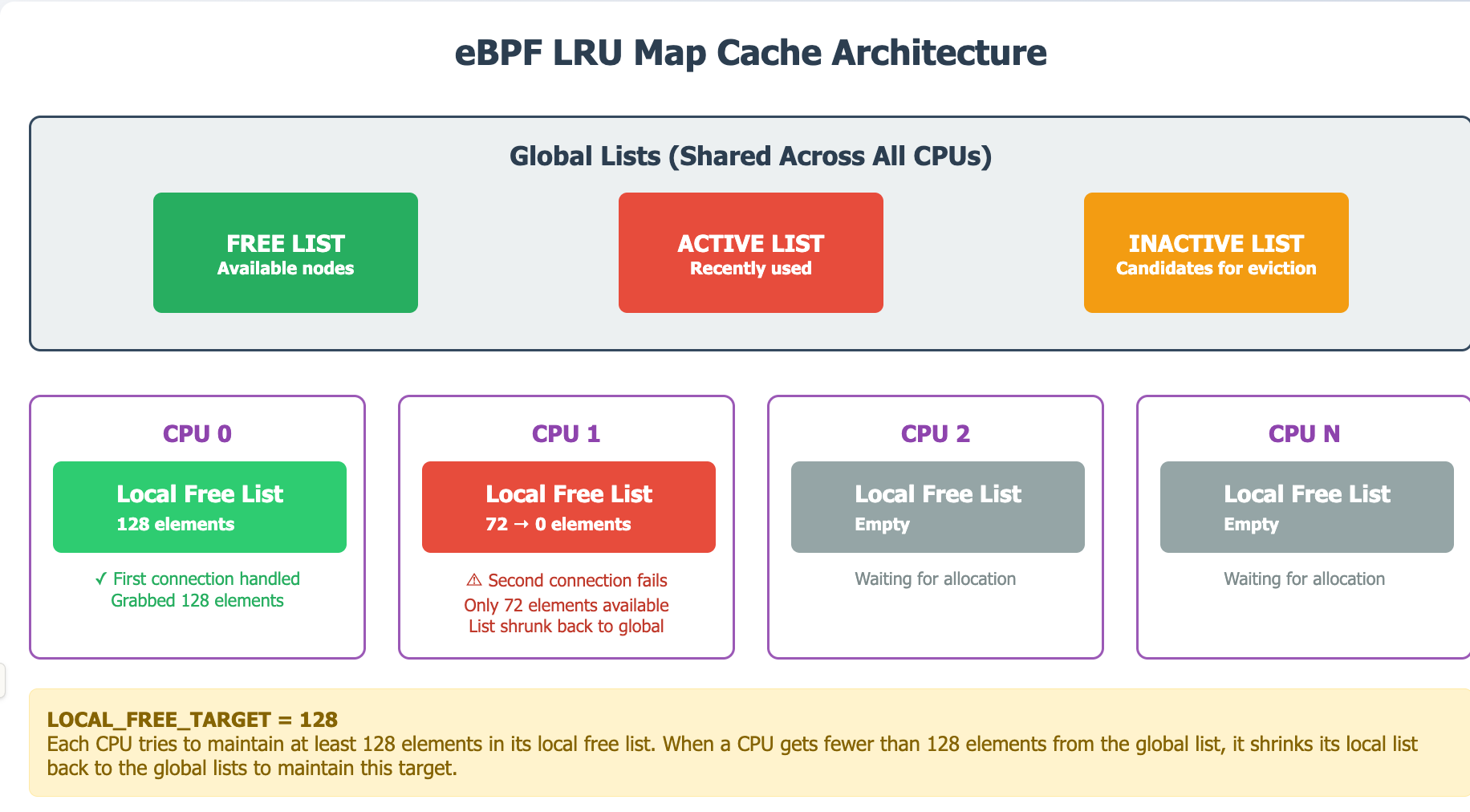
This all sounds very relevant to our issue! The commit even mentioned a magic number: 128. Under this logic, what happened in our eBPF program is:
- Initially 200 elements are all owned by global list.
- First CPU core handle the first connection, grab 128 element to its own free list.
- Second CPU handling second connection, trying to grab free element, but only able to get 72.
But why the second CPU trying to update second connection still fail to locate the element? We are still missing some crucial part in the puzzle.
Step 4, better understanding of LRU cache logic
With LLM's help I identified the function that pop element from global list to per CPU is bpf_lru_list_pop_free_to_local . With some bpftrace script,
sudo bpftrace -v -e ' kretfunc:bpf_lru_list_pop_free_to_local {
printf("bpf_lru_list_pop_free_to_local returned:\n");
print(kstack);
printf("\n");
}'I now obtained a very detailed stacktrace as below.
bpf_lru_list_pop_free_to_local returned:
bpf_prog_aec4be3a0686446b_kretfunc_vmlinux_bpf_lru_list_pop_free_to_local+150
bpf_trampoline_6442574642+108
bpf_lru_list_pop_free_to_local+5
bpf_lru_pop_free+245
prealloc_lru_pop+34
htab_lru_map_update_elem+130
bpf_prog_452d26ec47bd1425_my_ebpf_program+871
cls_bpf_classify+340
__tcf_classify+318
tcf_classify+255
tc_run+163Following the stacktrace function, you can clearly see that when LRU map tries to allocate a element, it first check the local CPU's free list
static struct bpf_lru_node *bpf_common_lru_pop_free(struct bpf_lru *lru, u32 hash)
node = __local_list_pop_free(loc_l);
if (!node) {
bpf_lru_list_pop_free_to_local(lru, loc_l);
node = __local_list_pop_free(loc_l);
}If that fails, it pops from the global list in bpf_lru_list_pop_free_to_local , https://elixir.bootlin.com/linux/v6.8/source/kernel/bpf/bpf_lru_list.c#L344
static void bpf_lru_list_pop_free_to_local(struct bpf_lru *lru,
struct bpf_lru_locallist *loc_l)
{
struct bpf_lru_list *l = &lru->common_lru.lru_list;
struct bpf_lru_node *node, *tmp_node;
unsigned int nfree = 0;
list_for_each_entry_safe(node, tmp_node, &l->lists[BPF_LRU_LIST_T_FREE],
list) {
__bpf_lru_node_move_to_free(l, node, local_free_list(loc_l),
BPF_LRU_LOCAL_LIST_T_FREE);
if (++nfree == LOCAL_FREE_TARGET)
break;
}
if (nfree < LOCAL_FREE_TARGET)
__bpf_lru_list_shrink(lru, l, LOCAL_FREE_TARGET - nfree,
local_free_list(loc_l),
BPF_LRU_LOCAL_LIST_T_FREE);
Most importantly, when nfree < LOCAL_FREE_TARGET(128) Kernel would try to shrink the local free list! This means when second CPU handles the second connection, with only 72 (200 - 128) elements returned from global list, it would shrink its local list back to global list. As part of that shrinking, the element for second connection is marked as inactive in the global list, and the CPU 2 its own free list is empty. Next time, CPU 2 tries to update the element, it would trigger another allocation from the global list and then effectively free
Bascially a cache trashing problem!
Step 5, One more experiment for verification
Both AI and I are very confident of this theory at this point. However a theory is only useful if it can predict something.
I first ran another bpftrace with __bpf_lru_list_shrink and clearly saw it's also being invoked as expected.
__bpf_lru_list_shrink called:
__bpf_lru_list_shrink.isra.0+1
bpf_trampoline_6442574642+57
bpf_lru_list_pop_free_to_local+5
bpf_lru_pop_free+245
prealloc_lru_pop+34
htab_lru_map_update_elem+130
bpf_prog_452d26ec47bd1425_my_ebpf_program+843
cls_bpf_classify+340
__tcf_classify+318
tcf_classify+255Next, if local CPU list would be shrinked when the element obtained is less than 128, we should see:
- A total size of 255 should still have the same behavior, CPU for second connection cannot find its own writes.
- A total size of 256 should be able to let first and second connection handled without issue: both CPU successfully grabbed 128 local elements, but 3rd connection fail with the same pattern.
I updated LRU map size and run the test again, and that's exactly what happened.
Final Thoughts
eBPF LRU map eviction logic initially is counterintuitive but after digging more, the behavior is understandable. To avoid such extreme cache trashing issue, evicting what you just inserted, it's better to keep the cache size at least 128 * Number of Cores + buffer.
Could the kernel handle this better? Maybe but that's even more complexity.
Finally I appreciate of the AI's advancement in our era, enabling someone without much Kernel experience to dive deeply of a problem. Of course ability to analyze the problem, making hypothesis, experimenting iteratively is always a core skill.
Please feel free to reach out at hujianfei258 🕸️ gmail.com if you have some thoughts!